

Have you ever wondered how a travel website can check prices on 500 airlines in seconds without getting blocked? The answer isn’t a secret trick, but a clever digital tool that acts as a master of disguise. This tool is one of the most important ingredients for making the modern internet work, allowing businesses to gather information, compare products, and manage their presence online at a scale that would otherwise be impossible. Select the best proxies for social media accounts.
To understand its power, we first have to look at the problem it solves. On the internet, your computer has a unique identifier, like a digital fingerprint, called an IP address. When a single IP address sends thousands of requests to a website in just a few minutes—say, to check the price of every shoe in a store—the website’s security systems often flag it as suspicious activity. This looks less like a curious shopper and more like a disruptive robot, and the site will quickly block it.
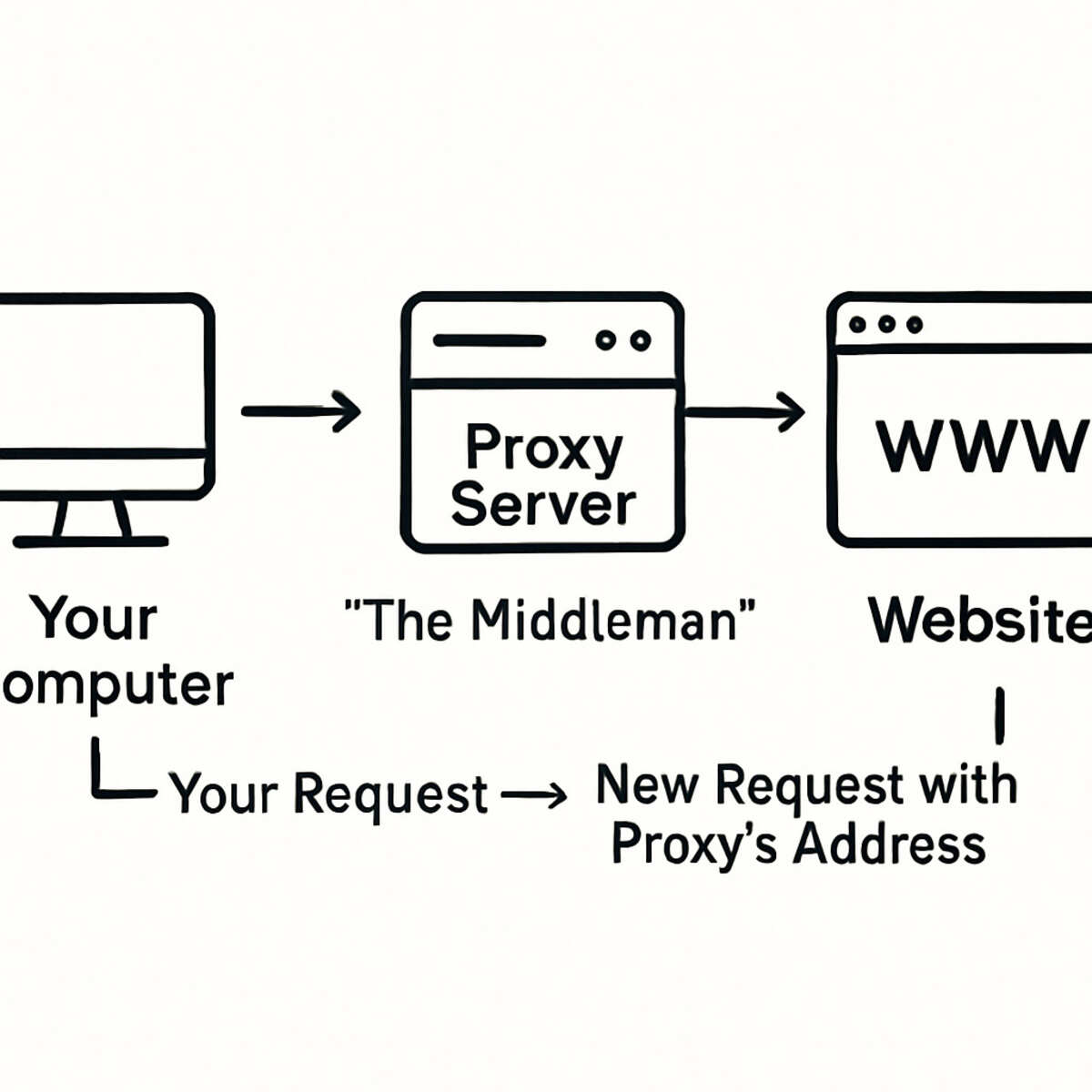
This is where a proxy comes in. A proxy is simply a middleman server that stands between your computer and the website you’re visiting. Instead of talking directly to the site, your request goes to the proxy first. The proxy then forwards that request using its own IP address, effectively giving your computer a temporary new identity. The website sees the request from the proxy, not from you, and sends the information back.
By using many different proxies, an automated task can look like it’s coming from hundreds or thousands of different “people” all over the world. This is the core principle behind using proxies for automation: they allow essential but repetitive tasks to run smoothly without triggering alarms.
Table of Contents
What Is Your Digital ‘Mailing Address’ and Why Does It Matter?
Every device connected to the internet, from your laptop to your smartphone, is assigned a unique identifier called an IP address. Think of it as the digital mailing address for your device. When you type a website into your browser, your computer sends a request out into the internet and includes its IP address so the website knows where to send the information back. Without it, you’d be sending letters with no return address.
However, this digital address reveals more than just a destination for data. It also tells websites two crucial things about you: your identity (that all requests are coming from the same device or network) and your general physical location, often down to your city or state. This is how a news website can show you local weather, or how a streaming service knows which country’s content library to display.
For a person casually browsing, this system works perfectly. But for automation, it presents a major roadblock. Imagine a business wanting to check the price of 500 different products on a competitor’s site. If an automated tool makes all those requests from a single IP address within minutes, it’s a massive red flag. This process, often part of web scraping, looks unnatural to the website, which is designed to block this kind of activity. The site sees one “person” acting inhumanly fast and shuts the door. Avoiding IP blocks is a central challenge for any large-scale automated task.
How a Digital ‘Middleman’ Gives Your Automation an Internet Disguise
If making hundreds of requests from a single digital address is a red flag, the logical solution is to get more addresses. This is where a proxy server comes in. Think of it as a professional middleman for your internet traffic, a core component of modern proxy solutions.
At their heart, proxies are intermediary servers that sit between your computer and the website you want to visit. The process works like a simple forwarding service:
- Instead of sending your request directly to the website, your computer sends it to the proxy server first.
- The proxy server then sends that same request to the website, but it replaces your IP address with its own.
- When the website responds, it sends the information back to the proxy, which then forwards it seamlessly back to you.
The result is a perfect digital disguise. To the website, the request appears to come from the proxy server, not from you. It does not know your real IP address or location. Most automation tools are simply configured to route their traffic this way, making the entire process invisible from the user’s perspective.
By using a proxy, a single automated tool suddenly gains the ability to look like it’s coming from anywhere in the world. By using a pool of different proxies, it can make a thousand requests look like they came from a thousand different people. This is the key to operating at scale without setting off a website’s built-in digital alarms.
Why 1,000 Visitors Are Normal, But 1 Visitor Making 1,000 Requests Is a Threat
Websites have digital alarms for a simple reason: stability and security. Imagine a popular new restaurant that can comfortably serve a hundred different customers over an hour. Now, picture one single person walking in and trying to place a hundred separate orders all at once. The kitchen would be overwhelmed, service would grind to a halt for everyone else, and the staff would rightly get suspicious. Websites operate on a similar principle. They are built to handle traffic from many different users, but they can be easily overwhelmed if one user starts demanding too much, too fast.
This built-in safety rule is known as rate limiting. It’s a digital speed limit for each visitor. A website might decide that any single IP address can only request, say, 30 pages per minute. For a human casually browsing, this limit is unnoticeable. But an automated tool—a “bot”—works at lightning speed, potentially trying to make hundreds of requests in seconds. The moment it crosses that threshold, the website’s system flags the IP address as hostile or broken and automatically blocks it. This is a primary reason why running automation without proxies for bots is almost guaranteed to fail.
From the website’s point of view, this isn’t about blocking legitimate research; it’s about self-preservation. A sudden flood of requests from one address doesn’t look like a price checker—it looks like a cyberattack designed to crash the server or an aggressive attempt to steal its data. This is why avoiding IP blocks with proxies is not just about hiding, but about blending in. The challenge for automation isn’t just getting a disguise; it’s making one fast-moving bot look like a crowd of slow, ordinary visitors.
How Proxies Make One Bot Look Like Thousands of Real People
If a single, hyperactive visitor is a red flag, automation gets around the problem by never looking like the same person twice. Instead of using one disguise over and over, an automated tool uses a new one for every single action it takes. This is the central value of using proxies for automation: they provide a near-endless supply of different identities.
This strategy of constantly changing IP addresses is known as IP rotation. Imagine an automated tool needs to check the price of 500 different products on an e-commerce site. Instead of sending 500 requests from one IP address (which would trigger an immediate block), it asks a proxy service for a different IP address for each request. To the website’s servers, this doesn’t look like one bot working at high speed. It looks like 500 completely different people from various locations, each visiting one page, which is perfectly normal online behavior.
These different IP addresses are drawn from a proxy pool, which is a massive collection of available IPs that the automation tool can use. Think of it as a digital costume shop with millions of outfits. For each task, the bot borrows a new “disguise” (an IP address), completes its request, and then returns it to the pool. The larger the pool, the more convincing the operation, as the chances of repeating the same IP address become vanishingly small.
By combining a fast-moving bot with a large, rotating proxy pool, a single program can accomplish what would otherwise seem impossible. It can gather vast amounts of information without ever drawing attention to itself, blending into the digital crowd. Not all disguises are created equal, however, as some are much more convincing than others.
Datacenter vs. Residential: Choosing the Right ‘Quality’ of Disguise
Just as a spy might choose between a simple fake mustache and a full prosthetic mask, the proxy “disguises” used in automation come in different levels of quality. The source of the IP address determines how believable it is to a website’s security systems. This brings us to the two main types of proxy solutions available: datacenter and residential proxies.
The first and most common type is the datacenter proxy. These are IP addresses that come from a massive commercial building full of computers—a data center. They are created in bulk, making them fast, cheap, and widely available. However, because these IPs all originate from known commercial servers rather than residential neighborhoods, websites can easily recognize them. For simple, low-stakes tasks, a datacenter proxy might be sufficient, but its disguise is often too obvious for more serious jobs.
On the other end of the spectrum are residential proxies. These are the master-class disguises of the internet. A residential proxy uses an IP address that has been assigned by an Internet Service Provider (like Comcast or Verizon) to a real home. When an automated task uses a residential proxy, the website sees the request as coming from a regular person’s laptop in their living room. This makes the traffic look completely authentic and far less likely to be blocked. The debate over residential vs datacenter proxies for scraping sensitive sites almost always ends here; the authenticity of a residential IP is unmatched.
The choice depends entirely on the mission. If a bot is performing a simple task on a website with low security, a cheap and fast datacenter proxy is a practical tool. But for sensitive operations where getting blocked would mean failure—like gathering competitive prices from a major e-commerce site—nothing beats the legitimacy of a residential proxy.
Use Case 1: How Price Comparison Sites Check a Million Items Instantly
Have you ever used a website to find the cheapest price on a new laptop or pair of headphones? In seconds, you see a neat list of prices from a dozen different online stores. Behind that magic is a massive automation effort. If one computer tries to ask an e-commerce giant like Amazon for the price of 10,000 different items in just a few minutes, Amazon’s digital security guards will spot the robotic activity and immediately block it.
This is where the power of residential proxies becomes essential. Instead of sending all its requests from a single, suspicious address, the price comparison engine uses a vast network of residential proxies. Its automated “shopper” bot asks for the price of the first item while appearing to be a user in Ohio. For the next item, it uses a different proxy and looks like a completely separate user in California. It repeats this thousands of times per minute, using a new residential IP for each request.
To the e-commerce store’s servers, this intense data gathering doesn’t look like one bot working at impossible speeds. Instead, it looks like thousands of individual, authentic shoppers browsing the site normally from their homes. This illustrates the core difference in the residential vs datacenter proxies for scraping debate; the believability of the residential IP is key to remaining undetected. The automated system gets the price and stock information it needs without ever setting off an alarm.
This sophisticated use of web scraping proxies is the foundation of the entire price comparison business model. It allows for large-scale data extraction that would otherwise be impossible, ensuring the information you see is accurate and up-to-the-minute.
Use Case 2: The Secret to Managing 50 Social Media Accounts From One Laptop
Beyond gathering data, proxies are crucial for managing a brand’s presence across the internet. Imagine you’re a marketing agency responsible for the social media accounts of 20 different clients. If you log into all 20 accounts from the same office computer, platforms like Instagram and Facebook will quickly become suspicious. To them, one person accessing dozens of accounts from a single IP address looks like spam or fraudulent activity, which can get those valuable client accounts flagged or even permanently banned.
This is where the strategy for using proxies completely changes. Instead of rapidly changing your digital disguise, you need a consistent one for each identity. The solution involves assigning a single, dedicated proxy to each social media account. This requires a feature known as a “sticky session.” When comparing sticky vs rotating IP sessions, a sticky IP is like a digital keycard for a specific account—it ensures the account is always accessed from the same IP address, creating a stable and believable history. Account #1 always looks like it’s being managed from a home in Chicago, while Account #2 always appears to be in Miami.
By creating this one-to-one relationship between an account and its proxy, the agency’s activity appears perfectly normal to the social media platform. Each login looks like an authentic user accessing their own account from their usual location, eliminating the risk of a security lockdown. This focus on long-term consistency is what makes a dedicated proxy the best proxy type for social media bots and management tools, as it provides the stable proxy server authentication needed for secure account handling.
How Businesses See What Their Website Looks Like in Other Countries
The ability to choose a digital location is vital for seeing the world through your customers’ eyes. A global brand might have a website that shows different prices in Japan, different ads in Mexico, and a different language in France. How can their team in London verify this is all working correctly without booking a flight? They use geotargeting proxies for localized data. By using a proxy server located in a specific country, a business can instantly look at the internet as if they were physically there, giving them a true-to-life view of their customer’s experience.
This process is surprisingly straightforward and highlights how residential proxies work in practice. If that London-based company wants to check its prices in Tokyo, it simply routes its connection through a residential proxy with a Japanese IP address. When they visit their own website, the site’s server sees a request from what appears to be an ordinary home internet connection in Tokyo and serves up the local version. Businesses use this to confirm that currency is correctly displayed, regional promotions are active, and international ad campaigns are running as intended, ensuring a consistent brand experience for customers everywhere.
For large-scale market research, businesses use automated tools with web scraping proxies to gather this information continuously from hundreds of different locations. This constant need for new perspectives brings up an important strategic choice: for some tasks, you need a stable, unchanging identity. For others, you need to change it every few seconds.
Changing Disguises: When to Rotate IPs vs. When to Keep the Same One
The choice between keeping one digital disguise or constantly swapping it for a new one depends entirely on the job. For automation, this decision is known as choosing between sticky vs rotating IP sessions, and getting it right is fundamental to success. Each strategy serves a distinct purpose, tailored to how a target website thinks and operates.
For massive data collection, constant change is the key. These are the best IP rotation strategies for data extraction. Imagine a company trying to check the price of 10,000 products on a competitor’s website. If all those requests come from a single IP address, it’s an obvious red flag. By rotating to a new proxy IP for every single request, the automated tool looks like 10,000 different, unrelated shoppers. This constant change allows the tool to blend into the crowd and gather information without being detected.
However, some tasks demand consistency. Think about any action that requires you to stay logged in, like managing a social media profile or filling a shopping cart. If your IP address changes between adding an item to your cart and clicking “checkout,” the website might get confused, think it’s a security risk, and end your session. For these jobs, a “sticky” session is used, which keeps the same IP address for a set duration—say, 10 or 30 minutes—giving the automation tool a stable identity to complete its multi-step work.
Choosing the right session type is non-negotiable for a successful outcome. Manually managing a complex library of disguises, or proxy pool management, would be a nightmare. Fortunately, a more elegant solution exists that acts as a single, intelligent gateway to the entire pool.
What is a Backconnect Proxy? Your ‘Magic Gateway’ to a Huge Pool of IPs
The elegant solution to the nightmare of proxy pool management is the backconnect proxy. Think of it as a VIP concierge service for your internet traffic. Instead of you having to find and switch to a new IP address for every single task, you simply give all your requests to this one trusted concierge. It then handles all the complicated work for you, automatically sending each request out from a different “disguise” from its vast network.
The genius of this system is its simplicity. From your automation tool’s perspective, it only ever connects to one single, stable address—the backconnect proxy’s gateway. Behind that gateway, a powerful server constantly dips into its massive pool of IPs, assigns a fresh one for each task, and sends it on its way. This perfects your IP rotation strategies without you ever having to see or manage the thousands of proxies involved.
This “magic gateway” is what makes large-scale data gathering not just possible, but practical. It’s the technology that allows a price comparison engine to check a thousand products in a minute or a brand to monitor its online reputation across the globe. With such powerful tools comes a responsibility to use them correctly, drawing a clear line between gathering data and disrupting services.
A Tool, Not a Crime: Understanding Ethical Web Scraping with Proxies
The idea of using proxies and automated “bots” can feel like digital espionage. But like any powerful tool, from a hammer to the internet itself, a proxy’s ethical standing comes down to how it’s used. It isn’t inherently good or bad; the intent and behavior of the user matter. The vast majority of automation powered by proxies is not malicious, but a core part of modern business and research.
At its heart, ethical scraping is about gathering publicly available information respectfully. Think of a price comparison website checking product prices on Amazon, or a travel company searching for the best flight deals. This is legitimate business intelligence. The line is crossed when automation is used to steal private data, disrupt a website by overwhelming it with traffic, or hoard a limited resource, like buying all the tickets to a popular concert before real fans get a chance.
Responsible automation also means being a polite digital visitor. Most websites have a public file called robots.txt, which works like a “welcome mat” with a set of rules for automated visitors. It might say, “Please don’t visit these specific pages,” or “Please wait a few seconds between requests.” Ethical web scraping with proxies always involves programming bots to find, read, and obey these rules.
Ultimately, using proxies for bots is about blending in, not breaking in. By distributing requests across many different IP addresses, proxies help an automated tool behave less like a single, aggressive machine and more like a crowd of individual, casual visitors. This respects the website’s resources, helps in avoiding IP blocks legitimately, and ensures the internet remains a shared, functional space for everyone.
Seeing the Invisible: How Proxies Now Shape Your Everyday Internet
Before, the internet might have seemed like a place where things just magically happened. Now, you can see the clever mechanics behind that magic. You understand that the internet has rules and gatekeepers, and that doing anything at a large scale requires a way to navigate those rules without being shut down.
You’ve learned that this navigation hinges on managing digital identity. Every device has a “digital mailing address” (its IP address), and proxies for automation act as the ultimate disguise. By using these clever middlemen, a single automated process—like those using web scraping proxies—can look like thousands of individual visitors. These proxy solutions are the invisible engine that allows businesses to gather data, monitor prices, and operate on a global scale.
This new understanding is a lens for viewing the digital world. The next time you use a travel aggregator to find the cheapest flight or see product prices updated in real-time, you’ll recognize the invisible work of proxies. You are no longer just seeing the result; you’re seeing the strategy. You now have a mental model to understand a fundamental part of how the modern internet functions.